Python 中的单神经元神经网络
pythonprogrammingserver side programming
神经网络是深度学习非常重要的核心;它在许多不同领域都有许多实际应用。如今,这些网络用于图像分类、语音识别、对象检测等。
让我们了解一下这是什么以及它是如何工作的?
这个网络有不同的组件。它们如下 −
- 输入层,x
- 任意数量的隐藏层
- 输出层,ŷ
- 每层之间的一组权重和偏差,由 W 和 b 定义
- 接下来是每个隐藏层的激活函数选择,σ。
此图显示了 2 层神经网络(计算神经网络中的层数时通常不包括输入层)
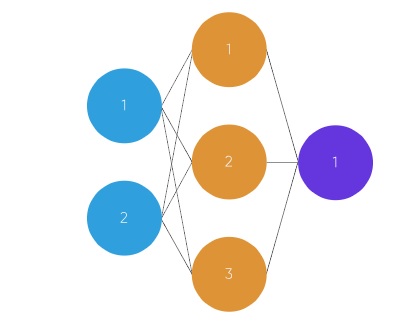
在此图中,圆圈代表神经元,线条代表突触。突触用于乘以输入和权重。我们认为权重是神经元之间连接的"强度"。权重定义神经网络的输出。
以下是简单前馈神经网络工作原理的简要概述 −
当我们使用前馈神经网络时,我们必须遵循一些步骤。
首先将输入作为矩阵(2D 数字数组)
接下来将输入乘以一组权重。
接下来应用激活函数。
返回输出。
接下来计算误差,它是数据的期望输出与预测输出之间的差异。
权重会根据误差略有变化。
为了进行训练,这个过程重复了 1,000 多次,训练的数据越多,我们的输出就越准确是。
学习时间、睡眠时间(输入)考试成绩(输出)
2, 992 1, 586 3, 689 4, 8?
示例代码
从 numpy 导入 exp、array、random、dot、tanh
class my_network():
def __init__(self):
random.seed(1)
# 3x1 权重矩阵
self.weight_matrix = 2 * random.random((3, 1)) - 1
defmy_tanh(self, x):
返回 tanh(x)
defmy_tanh_derivative(self, x):
return 1.0 - tanh(x) ** 2
# 前向传播
defmy_forward_propagation(self, input):
return self.my_tanh(dot(inputs, self.weight_matrix))
# 训练神经网络。
deftrain(self, train_inputs, train_outputs,
num_train_iterations):
for iteration in range(num_train_iterations):
output = self.my_forward_propagation(train_inputs)
# 计算输出中的误差。
error = train_outputs - output
adjustment = dot(train_inputs.T, error *self.my_tanh_derivative(output))
# 调整权重矩阵
self.weight_matrix += adjustment
# 驱动代码
if __name__ == "__main__":
my_neural = my_network()
print ('训练开始时的随机权重')
print (my_neural.weight_matrix)
train_inputs = array([[0, 0, 1], [1, 1, 1], [1, 0, 1], [0, 1, 1]])
train_outputs = array([[0, 1, 1, 0]]).T
my_neural.train(train_inputs, train_outputs, 10000)
print ('训练后显示新权重')
print (my_neural.weight_matrix)
# 使用新情况测试神经网络。
print ("在新示例上测试网络 ->")
print (my_neural.my_forward_propagation(array([1, 0, 0])))
输出
Random weights when training has started [[-0.16595599] [ 0.44064899] [-0.99977125]] Displaying new weights after training [[5.39428067] [0.19482422] [0.34317086]] Testing network on new examples -> [0.99995873]

