如何通过遍历每一行在 Python 中创建相关矩阵?
相关矩阵是一个包含许多变量的相关系数的表。表中的每个单元格代表两个变量之间的相关性。该值可能介于 -1 和 1 之间。相关矩阵用于汇总数据、诊断高级分析以及作为更复杂研究的输入。
相关矩阵用于表示数据集中变量之间的关系。它是一种帮助程序员分析数据组件之间关系的矩阵。它表示 0 和 1 之间的相关系数。
正值表示相关性好,负值表示相关性弱/低,零值 (0) 表示给定变量集之间没有依赖关系。
回归分析和相关矩阵显示了以下观察结果 −
识别数据集中独立变量之间的关系。
有助于从数据集中选择重要且非冗余的变量。
这仅适用于数字或连续的变量。
在本文中,我们将向您展示如何使用 python 创建相关矩阵。
假设我们已经获取了一个名为 starbucksMenu.csv 的 CSV 文件,其中包含一些随机数据。我们需要为数据集中指定的列创建一个相关矩阵并绘制相关矩阵。
输入文件数据
starbucksMenu.csv
| Item Name | Calories | Fat | Carb | Fiber | Protein | Sodium |
| Cool Lime Starbucks Refreshers™ | 45 | 0 | 11 | 0 | 0 | 10 |
| Evolution Fresh™ Organic Ginger Limeade | 80 | 0 | 18 | 1 | 0 | 10 |
| Iced Coffee | 60 | 0 | 14 | 1 | 0 | 10 |
| Tazo® Bottled Berry Blossom White | 0 | 0 | 0 | 0 | 0 | 0 |
| Tazo® Bottled Brambleberry | 130 | 2.5 | 21 | 0 | 5 | 65 |
| Tazo® Bottled Giant Peach | 140 | 2.5 | 23 | 0 | 5 | 90 |
| Tazo® Bottled Iced Passion | 130 | 2.5 | 21 | 0 | 5 | 65 |
| Tazo® Bottled Plum Pomegranate | 80 | 0 | 19 | 0 | 0 | 10 |
| Tazo® Bottled Tazoberry | 60 | 0 | 15 | 0 | 0 | 10 |
| Tazo® Bottled White Cranberry | 150 | 0 | 38 | 0 | 0 | 15 |
创建相关矩阵
我们将绘制数据集中三列独立连续变量的相关矩阵。
- 碳水化合物
- 蛋白质
- 钠
算法(步骤)
以下是执行所需任务需要遵循的算法/步骤 -
导入 os、pandas、NumPy 和 seaborn 库。
使用 read_csv() 函数读取给定的 CSV 文件(将 CSV 文件加载为 pandas 数据框)。
从给定数据集中创建必须为其创建相关矩阵的列的列表创建。
使用 corr() 函数创建相关矩阵(它计算数据框中所有列的成对相关性。任何 na(null) 值都会被自动过滤掉。对于数据框中的任何非数字数据类型列,它都会被丢弃)。
打印数据集指定列的相关矩阵。
使用 heatmap() 函数绘制相关矩阵(对于要绘制的每个值,热图都有表示相同颜色的几种色调的值。图表的深色通常比较浅的色调表示更高的值。同样,可以使用完全不同的颜色(用于显著不同的值)来表示 seaborn 库。
将数据集导入 Pandas Dataframe
现在,我们首先将任何示例数据集(这里我们使用 starbucksMenu.csv )导入 pandas dataframe 并打印它。
示例 1
# Import pandas module as pd using the import keyword import pandas as pd # 读取数据集 givenDataset = pd.read_csv('starbucksMenu.csv') print(givenDataset)
输出
| Item Name | Calories | Fat | Carb | Fiber | Protein | Sodium |
| Cool Lime Starbucks Refreshers™ | 45 | 0 | 11 | 0 | 0 | 10 |
| Evolution Fresh™ Organic Ginger Limeade | 80 | 0 | 18 | 1 | 0 | 10 |
| Iced Coffee | 60 | 0 | 14 | 1 | 0 | 10 |
| Tazo® Bottled Berry Blossom White | 0 | 0 | 0 | 0 | 0 | 0 |
| Tazo® Bottled Brambleberry | 130 | 2.5 | 21 | 0 | 5 | 65 |
| Tazo® Bottled Giant Peach | 140 | 2.5 | 23 | 0 | 5 | 90 |
| Tazo® Bottled Iced Passion | 130 | 2.5 | 21 | 0 | 5 | 65 |
| Tazo® Bottled Plum Pomegranate | 80 | 0 | 19 | 0 | 0 | 10 |
| Tazo® Bottled Tazoberry | 60 | 0 | 15 | 0 | 0 | 10 |
| Tazo® Bottled White Cranberry | 150 | 0 | 38 | 0 | 0 | 15 |
导入数据集后创建相关矩阵
以下程序找出如何为给定的数据集创建相关矩阵,打印它们,并绘制相关矩阵 -
示例 2
import os # 导入 pandas 模块 import pandas as pd import numpy as np import seaborn # 读取数据集 givenDataset = pd.read_csv('starbucksMenu.csv') # 从数据集分配列列表 numericColumns = ['Carb','Protein','Sodium'] # 创建相关矩阵 correlationMatrix = givenDataset.loc[:,numericColumns].corr() # 打印相关矩阵。 print(correlationMatrix) # 显示相关矩阵 seaborn.heatmap(correlationMatrix, annot=True)
输出
执行时,上述程序将生成以下输出 -
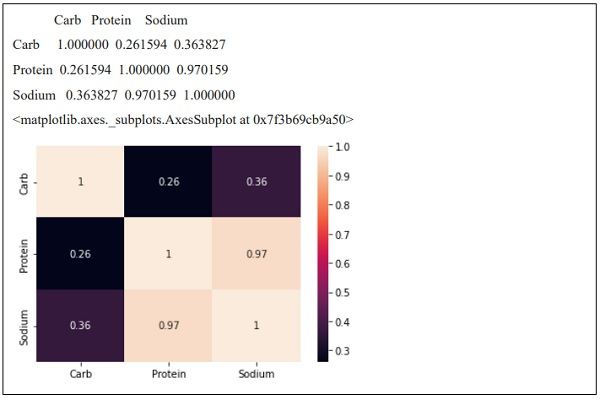
You learned how to compute a correlation matrix using Python and Pandas in this tutorial. Along with that you have learned how to generate a correlation matrix using the Pandas corr() method and also how to utilize the Seaborn library's heatmap function to show a matrix, allowing you to better visualize and understand the data at a glance.

