使用 Python 中的 ARIMA 模型进行预测
ARIMA 是一种用于时间序列预测的统计模型,它结合了三个组件:自回归 (AR)、积分 (I) 和移动平均 (MA)。
自回归 (AR) - 此组件模拟观察值与滞后观察值之间的依赖关系。它基于时间序列的过去值可用于预测未来值的理念。自回归的阶数(用"p"表示)指定用作预测因子的滞后观察值的数量。
积分 (I) - 此组件通过消除趋势和季节性来处理时间序列数据的非平稳性。积分阶数用"d"表示,是原始时间序列数据需要差分的次数,以使其平稳,即消除趋势和季节性。
移动平均 (MA) - 此组件模拟应用 AR 和 I 组件后时间序列残差之间的依赖关系。移动平均阶数用"q"表示,指定用作预测因子的滞后残差误差的数量。
ARIMA 模型的一般形式是 ARIMA (p, d, q),其中 p、d 和 q 分别是自回归、积分和移动平均的阶数。要使用 ARIMA 模型进行预测,必须首先确定最适合数据的 p、d 和 q 的值。这可以通过称为模型选择的过程来实现,该过程涉及使用 p、d 和 q 的不同组合拟合各种 ARIMA 模型,并选择误差最小的模型。
预测未来 12 个月的销售额
使用 ARIMA 预测销售额是使用统计技术根据公司的历史销售数据预测其未来销售额的过程。该过程通常按以下步骤进行:
收集历史销售数据并将其转换为时间序列格式。
可视化数据以识别任何趋势、季节性或模式。
确定使时间序列平稳所需的差分顺序。
根据数据中的模式选择 ARIMA 模型 (p、d、q) 的顺序。
将 ARIMA 模型拟合到数据并预测未来的销售情况。
评估模型的性能并根据需要进行调整。
使用该模型对未来销售进行预测并根据预测做出决策。
ARIMA 是一种流行的销售预测方法,因为它可以捕获数据中的复杂模式,并处理时间序列中的趋势和季节性。但是,模型的性能可能受到各种因素的影响,例如数据的质量、参数的选择以及模型捕获数据中潜在模式的能力。
现在让我们看一个使用 ARIMA 进行预测的示例。
下面使用的数据集 (sales_data.csv) 可在此处获得。
示例
import pandas as pd
import numpy as np
import statsmodels.api as sm
import matplotlib.pyplot as plt
# 加载 时间序列 数据
data = pd.read_csv('sales_data.csv')
# 拟合 ARIMA 模型
model = sm.tsa.ARIMA(data['sales'], order=(2, 1, 1))
model_fit = model.f it()
# 预测未来值
forecast = model_fit.forecast(steps=12)
# 打印预测
print(forecast[0])
# 绘制时间序列
data2=np.append(data,forecast[0])
plt.plot(data2)
plt.xlabel('日期')
plt.ylabel('销售额')
plt.title('合成时间序列数据')
plt.show()
输出
[56.29545598 56.60345925 56.90298063 57.19449608 57.47839568 57.7550522 58.02482013 58.28803659 58.54502221 58.79608193 59.04150576 59.28156952]
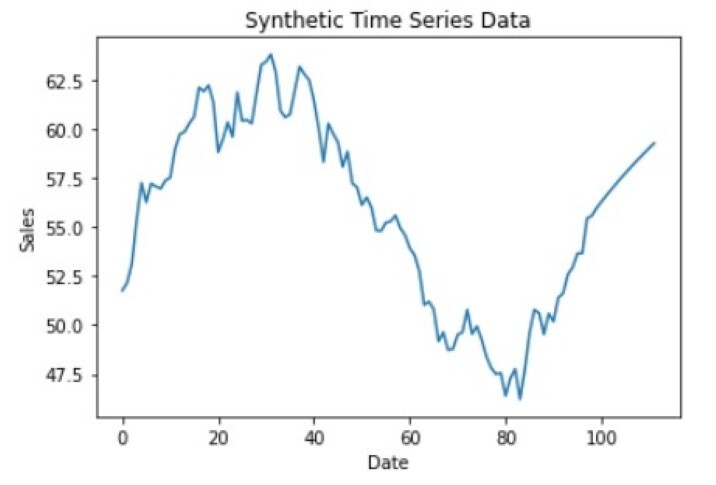
在此示例中,时间序列数据是特定产品的销售数据,从 CSV 文件加载到 pandas 数据框中。使用 sm.tsa.ARIMA 函数将 ARIMA 模型拟合到销售数据,将自回归阶设置为 2,将积分阶设置为 1,将移动平均阶设置为 1。
然后使用 model_fit 对象生成未来销售预测,使用带有 steps 参数 12 的预测方法来指定要预测的未来值的数量。然后打印预测,给出未来 12 个月的预期销售值。
自定义数据集
在此,我们将在代码本身中定义数据集。数据最初将以列表的形式出现,随后将转换为 Pandas 数据框。
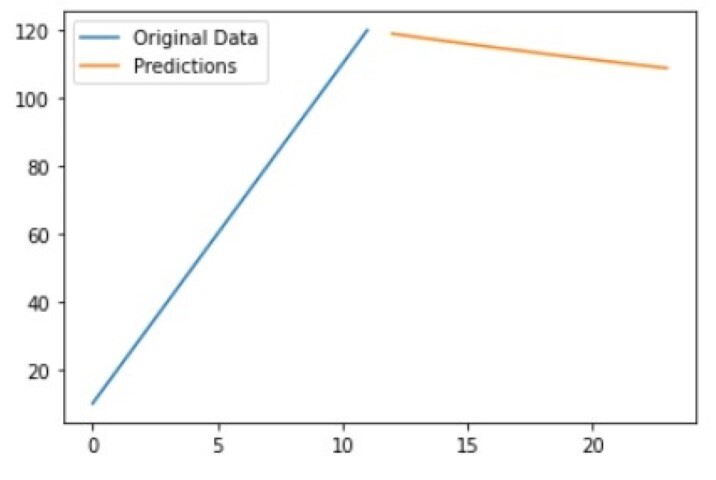
然后,此代码将 ARIMA 模型拟合到自定义数据集,对接下来的 12 个时间步骤进行预测,并将预测存储在 predictions 变量中。在此示例中,自定义数据集是 12 个值的列表,但拟合 ARIMA 模型和进行预测的过程对于任何时间序列数据都是相同的。
示例
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from statsmodels.tsa.arima.model import ARIMA
# 加载 自定义数据集
data = [10, 20, 30, 40, 50, 60, 70, 80, 90, 100, 110, 120]
# 将 数据 转换为 pandas DataFrame
df = pd.DataFrame({'values': data})
# 拟合 ARIMA 模型el
model = ARIMA(df['values'], order=(1,0,0))
model_fit = model.fit()
# 进行预测
predictions = model_fit.forecast(steps=12)
print(predictions)
# 绘制 原始数据集 和 预测值
plt.plot(df['values'], label='Original Data')
plt.plot(predictions, label='Predictions')
plt.legend()
plt.show()
输出
12 118.967858 13 117.955086 14 116.961320 15 115.986203 16 115.029385 17 114.090523 18 113.169280 19 112.265326 20 111.378335 21 110.507989 22 109.653977 23 108.815991 Name: predicted_mean, dtype: float64
波士顿住房数据集
import numpy as np
import pandas as pd
from statsmodels.tsa.arima.model import ARIMA
import matplotlib.pyplot as plt
from sklearn.datasets import load_boston
import warnings
warnings.filterwarnings("ignore")
# 加载 Boston 数据集
boston = load_boston()
data = boston.data
# 将 data 转换为 pandas DataFrame
df = pd.DataFrame(data, columns=boston.featur e_names)
df=df.head(20)
# 拟合 ARIMA 模型
model = ARIMA(df['CRIM'], order=(1,0,0))
model_fit = model.fit()
# 进行预测
predictions = model_fit.forecast(steps=12)
print(predictions.tolist())
# 绘制原始数据集和预测
plt.plot(df['CRIM'], label='Original Data')
plt.plot(predictions, label='Predictions')
plt.legend()
plt.show()
输出
[0.6738187961066762, 0.6288621548198372, 0.5899808007068923, 0.5563537401796019, 0.5272709259231514, 0.5021182639951554, 0.4803646470141665, 0.46155073963886595, 0.44527927953934654, 0.4312066890620576, 0.41903582046573945, 0.40850968154143097]
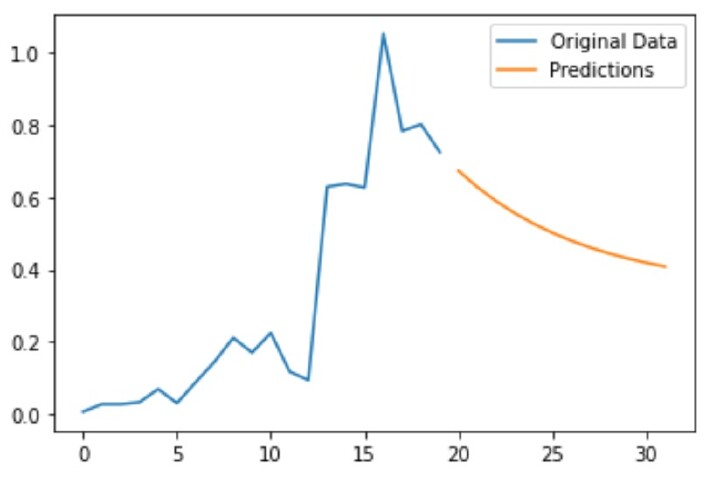
图表中的所有 X 值均采用索引值的形式。
结论
ARIMA 是一种强大的时间序列预测方法,可用于在 Python 中预测股票价格。使用 ARIMA 进行预测的过程包括将时间序列数据转换为平稳格式、确定差分、自回归和移动平均项的顺序、将 ARIMA 模型拟合到数据、生成预测以及评估模型的性能。Python 中的 statsmodels 库提供了一种方便有效的方法来执行 ARIMA 预测。然而,重要的是要记住,ARIMA 只是可用于股票价格预测的众多方法之一,并且模型的结果可能因所用数据的质量和特征而异。

