如何在 Seaborn 中操作数据以创建图表?
在 Seaborn 中,数据操作使用 pandas 完成,它是 Python 中流行的数据操作库。Seaborn 建立在 pandas 之上并与其无缝集成。Pandas 为数据操作提供了强大的数据结构和函数,例如过滤、分组、聚合和转换数据,这些都可以与 Seaborn 结合使用来创建图表。
通过将 pandas 的数据操作功能与 Seaborn 的绘图功能相结合,我们可以轻松地以简洁高效的方式操作和可视化我们的数据。这使我们能够有效地探索和传达来自数据集的见解。
以下是使用 Seaborn 中的 Pandas 库进行数据操作以创建图表的分步指南。
导入必要的库
由于我们正在使用 pandas 和 Seaborn 库,因此首先我们必须使用以下代码导入这两个库。
import seaborn as sns import pandas as pd
使用 pandas 加载或创建数据集
接下来,我们可以使用 pandas 库的 read_csv 和 DataFrame 加载或创建我们自己的数据集。在本文中,我们使用 pandas 库的 DataFrame() 函数创建数据集。
示例
import seaborn as sns
import pandas as pd
data = {'Name': ['Alice', 'Bob', 'Charlie'],
'Age': [25, 30, 35],
'Salary': [50000, 60000, 70000]}
df = pd.DataFrame(data)
print(df.head())
输出
Name Age Salary
0 Alice 25 50000
1 Bob 30 60000
2 Charlie 35 70000
执行数据操作
一旦我们将数据集放入 pandas DataFrame 中,我们现在可以使用各种数据操作技术来准备绘图数据。一些常见操作如下所述。
过滤
过滤用于根据某些条件选择行或列的子集。例如,如果我们想从创建的数据中过滤年龄大于 30 的行,则代码定义如下。
示例
import seaborn as sns
import pandas as pd
data = {'Name': ['Alice', 'Bob', 'Charlie'],
'Age': [25, 30, 35],
'Salary': [50000, 60000, 70000]}
df = pd.DataFrame(data)
df.head()
filtered_df = df[df['Age'] > 30]
res = filtered_df.head()
print(res)
输出
Name Age Salary
2 Charlie 35 70000
分组和聚合
根据一个或多个变量对数据进行分组并计算汇总统计数据。例如,当我们想按姓名对数据进行分组并计算平均工资时,将使用以下代码行。
示例
import seaborn as sns
import pandas as pd
data = {'Name': ['Alice', 'Bob', 'Charlie'],
'Age': [25, 30, 35],
'Salary': [50000, 60000, 70000]}
df = pd.DataFrame(data)
grouped_df = df.groupby('Name')['Salary'].mean()
print(grouped_df.head())
输出
Name Alice 50000.0 Bob 60000.0 Charlie 70000.0 Name: Salary, dtype: float64
数据转换
数据转换是指应用函数或转换来修改数据并根据现有列创建新列。
示例
import seaborn as sns
import pandas as pd
data = {'Name': ['Alice', 'Bob', 'Charlie'],
'Age': [25, 30, 35],
'Salary': [50000, 60000, 70000]}
df = pd.DataFrame(data)
df.head()
grouped_df = df.groupby('Name')['Salary'].mean()
res = grouped_df.head()
print(res)
输出
Name Alice 50000.0 Bob 60000.0 Charlie 70000.0 Name: Salary, dtype: float64
数据重塑
在数据重塑中,我们使用诸如旋转或融合之类的技术将数据重构为不同的格式。
示例
import seaborn as sns
import pandas as pd
data = {'Name': ['Alice', 'Bob', 'Charlie'],
'Age': [25, 30, 35],
'Salary': [50000, 60000, 70000]}
df = pd.DataFrame(data)
pivoted_df = df.pivot(index='Name', columns='Age', values='Salary')
print(pivoted_df.head())
输出
Age 25 30 35 Name Alice 50000.0 NaN NaN Bob NaN 60000.0 NaN Charlie NaN NaN 70000.0
使用 Seaborn 创建图表
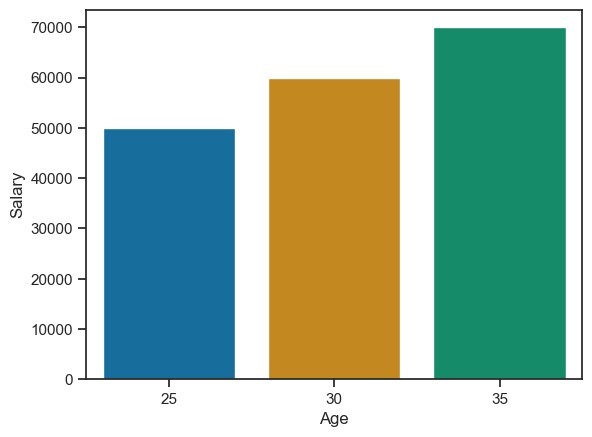
准备好数据后,我们可以使用 Seaborn 的绘图函数根据数据创建可视化效果。例如,当我们想要创建按年龄段划分的平均工资条形图时,
示例
import seaborn as sns
import pandas as pd
import matplotlib.pyplot as plt
data = {'Name': ['Alice', 'Bob', 'Charlie'],
'Age': [25, 30, 35],
'Salary': [50000, 60000, 70000]}
df = pd.DataFrame(data)
sns.barplot(x='Age', y='Salary', data=df)
plt.show()
输出
Seaborn 提供了广泛的绘图函数,包括散点图、线图、条形图、直方图、箱线图等等。这些函数接受 pandas DataFrames 作为输入,并提供自定义绘图外观和样式的选项。

