如何使用 Seaborn 按一列或多列对数据进行分组?
Seaborn 主要是一个数据可视化库,不提供按一列或多列对数据进行分组的直接方法。但是,Seaborn 可以与 pandas 库无缝协作,后者是 Python 中一个功能强大的数据操作库。我们可以使用 pandas 将数据按一列或多列分组,然后使用 Seaborn 将分组后的数据可视化。
通过将 pandas 的数据操作功能(按一列或多列对数据进行分组)与 Seaborn 的可视化功能相结合,我们可以从数据中获得见解,并通过可视化有效地传达我们的发现。
以下是有关如何结合使用 Seaborn 与 pandas 将数据按一列或多列分组的详细说明。
导入必要的库
在将数据按一列或多列分组之前,我们必须导入所有必需的库,例如 seaborn 和 pandas。
import seaborn as sns import pandas as pd
将数据加载到 pandas DataFrame 中
接下来,我们必须使用Pandas 库中提供了 read_csv() 函数。让我们使用 read_csv() 函数加载 Iris.csv 文件。
df = pd.read_csv("https://gist.githubusercontent.com/netj/8836201/raw/6f9306ad21398ea43cba4f7d537619d0e07d5ae3/iris.csv")
df.head()
按一列或多列对数据进行分组
Pandas 提供了 'groupby()' 函数,可根据一列或多列对数据进行分组。我们可以指定一个或多个列作为分组条件,然后对分组数据执行操作。
示例
在此示例中,我们创建一个"grouped_data'"对象,该对象表示基于指定列的分组数据。此对象可用于对分组数据执行各种操作。这里我们在单列和多列上应用了分组。
import seaborn as sns
import pandas as pd
df = pd.read_csv("https://gist.githubusercontent.com/netj/8836201/raw/6f9306ad21398ea43cba4f7d537619d0e07d5ae3/iris.csv")
df.head()
# 按单列对数据进行分组
grouped_data = df.groupby(['variety'])
# 按多列对数据进行分组
grouped_data = df.groupby(['sepal.length', 'sepal.width'])
res = grouped_data.head()
print(res)
输出
sepal.length sepal.width petal.length petal.width variety
0 5.1 3.5 1.4 0.2 Setosa
1 4.9 3.0 1.4 0.2 Setosa
2 4.7 3.2 1.3 0.2 Setosa
3 4.6 3.1 1.5 0.2 Setosa
4 5.0 3.6 1.4 0.2 Setosa
.. ... ... ... ... ...
145 6.7 3.0 5.2 2.3 Virginica
146 6.3 2.5 5.0 1.9 Virginica
147 6.5 3.0 5.2 2.0 Virginica
148 6.2 3.4 5.4 2.3 Virginica
149 5.9 3.0 5.1 1.8 Virginica
[150 rows x 5 columns]
对分组数据执行操作
对数据进行分组后,我们可以对分组数据执行各种操作,例如计算汇总统计数据、应用聚合或转换数据。
示例
在此示例中,我们计算每个组内 'sepal.length' 的平均值、每个组内 ''sepal.width' 和 'petal.length' 的总和,并应用自定义聚合函数来计算每个组内 'petal.width ' 的范围。
mean_values = grouped_data['sepal.length'].mean() sum_values = grouped_data['sepal.width', 'petal.length'].sum() custom_agg = grouped_data['petal.width'].agg(lambda x: x.max() - x.min())
使用 Seaborn 可视化分组数据
对分组数据执行操作后,我们可以使用 Seaborn 可视化分组数据。Seaborn 提供了各种绘图函数,可以接受 pandas DataFrames 作为输入。
我们可以使用各种其他 Seaborn 绘图函数来可视化分组数据,例如箱线图、小提琴图、点图等。Seaborn 提供了许多自定义选项来增强数据的视觉表现。
示例
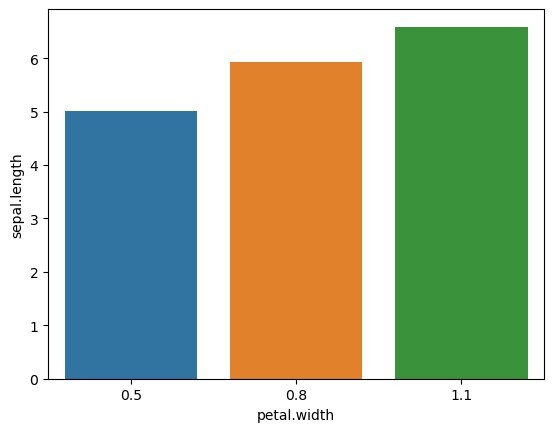
在此示例中,我们使用 Seaborn 中的"barplot()"函数创建每个组内平均值的条形图。 'x' 参数表示组的键,'y' 参数表示平均值。
import seaborn as sns
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv("https://gist.githubusercontent.com/netj/8836201/raw/6f9306ad21398ea43cba4f7d537619d0e07d5ae3/iris.csv")
# 按单个列对数据进行分组
grouped_data = df.groupby(['variety'])
mean_values = grouped_data['sepal.length'].mean()
sum_values = grouped_data['sepal.width', 'petal.length'].sum()
custom_agg = grouped_data['petal.width'].agg(lambda x: x.max() - x.min())
#创建每个组内平均值的条形图
sns.barplot(x = custom_agg, y = mean_values)
plt.show()
输出
注意
需要注意的是,Seaborn 主要专注于数据可视化,对于更复杂的数据操作任务,我们可能需要依赖 pandas 或 Python 中其他数据操作库提供的功能。

