Puppeteer - Xpath 函数
要唯一地确定一个元素,我们可以借助 html 标记中的任何属性,也可以使用 html 标记上的属性组合。大多数情况下使用 id 属性,因为它对于页面是唯一的。
但是,如果不存在 id 属性,我们可以使用其他属性,如 class、name 等。如果不存在 id、name 和 class 等属性,我们可以使用仅适用于该标记的独特属性或属性及其值的组合来标识元素。为此,我们必须使用 xpath 表达式。
如果元素有重复的属性或没有属性,则使用函数 text() 来标识元素。为了使用 text() 函数,元素必须具有页面上可见的文本。
语法
使用 text() 函数的语法如下 −
//tagname[text()='visible text on element']
如果元素或文本的值本质上是部分动态的或非常长,我们可以使用 contains() 函数。要使用contains()函数,元素必须具有属性值或文本。
语法
使用contains()函数的语法如下 −
//tagname[contains(@attribute,'value')] //tagname[contains(text(),'visible text on element')]
如果元素的文本以特定文本开头,我们可以对其使用starts-with()函数。
语法
使用starts-with()函数的语法如下 −
//tagname[starts-with(text(),'visible text on element')
在所有上述函数中,tagname都是可选的。我们可以使用符号 * 来代替标签名。
在下图中,让我们借助显示的文本识别元素 - Library,然后单击它。
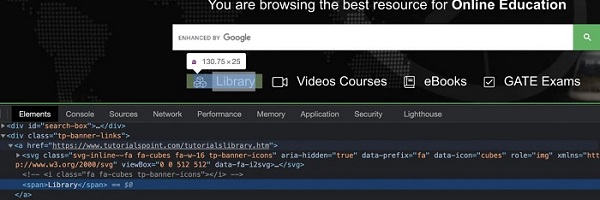
元素的 xpath 应为 //*[text()='Library']。
在这里,我们使用 xpath 选择器,因此我们必须使用方法:page.$x(xpath value)。此方法的详细信息在章节 - Puppeteer 定位器中讨论。
首先,请按照 Puppeteer 基本测试章节中的步骤 1 到 2 进行操作,如下所示 −
步骤 1 −在创建 node_modules 文件夹的目录(安装 Puppeteer 和 Puppeteer 核心的位置)内创建一个新文件。
有关 Puppeteer 安装的详细信息,请参阅 Puppeteer 安装一章。
右键单击创建 node_modules 文件夹的文件夹,然后单击新建文件按钮。
步骤 2 − 输入文件名,例如 testcase1.js。
步骤 3 −在创建的 testcase1.js 文件中添加以下代码。
//Puppeteer 库
const pt= require('puppeteer')
async function selectorFunTextXpath(){
//以 headless 模式启动浏览器
const browser = await pt.launch()
//浏览器新页面
const page = await browser.newPage()
//启动 URL
await page.goto('https://www.tutorialspoint.com/index.htm')
//使用 xpath 函数识别元素 - text() 然后单击
const b = (await page.$x("//*[text()='Library']"))[0]
b.click()
//等待一段时间
await page.waitForTimeout(4000)
//单击后获取 URL
console.log(await page.url())
}
selectorFunTextXpath()
步骤 4 − 使用下面给出的命令执行代码 −
node <filename>
因此在我们的示例中,我们将运行以下命令 −
node testcase1.js

成功执行命令后,单击元素库时导航到的页面的 URL - https://www.tutorialspoint.com/tutorialslibrary.htm 将在控制台中打印。

